


【导读】近日,人形机器人公司1X公布了世界模型挑战赛的二阶段:Sampling。一同登场的还有合作伙伴英伟达新发布的Cosmos视频分词器,超高质量和压缩率助力构建虚拟世界。
AI时代的机器人怎么训练?
去年3月,挪威人形机器人公司1X拿到了OpenAI领投的2350万美元,今年初又完成了1亿美元的B轮融资。
作为OpenAI投资的第一家硬件公司,1X给出的答案是:世界模型(World Model)。

在这个时代,世界模型将成为解决通用仿真和评估问题,实现安全、可靠、智能机器人的有效途径。
英伟达也表示,视频AI模型有望彻底改变机器人、汽车和零售等行业。
今年9月,1X介绍了自己的世界模型、新的高分辨率机器人数据集,并开启了一个三阶段的世界模型挑战赛。
10000美元挑战赛

第一个挑战是Compression,关于在极其多样化的机器人数据集上如何最大限度地减少训练损失。损失越低,模型就越能理解训练数据。
本阶段奖金10000美元,胜者为在给定的测试集实现损失8.0的第一个提交者。
截至小编码字的时刻,挑战依然有效。
第二个挑战Sampling于近日公布,侧重于通过给定前一帧序列来预测下一帧,从而产生连贯且合理的视频延续,准确反映场景的动态。

1X鼓励参赛者探索传统next-logit预测之外的各种未来预测方法。比如Generative Adversarial Networks(GAN)、Diffusion Models和MaskGIT等技术都可用于生成下一帧。
本阶段奖金同样为10000美元,要求提交的PSNR应达到26.5左右或更高,评估服务器将于2025年3月开放。
为了助力此方向的研究,1X发布了一个包含100小时原始机器人视频的新数据集,以及支持世界模型训练的机器人状态序列。

数据集地址:https://huggingface.co/datasets/1x-technologies
除此之外,1X还与英伟达的World Models团队合作,使用他们新发布的Cosmos视频分词器进一步处理视频序列,为机器人数据创建了高度压缩的时间表示。

1X World Model
在机器学习中,世界模型是一种计算机程序,可以想象世界如何响应智能体的行为而演变。
自动驾驶领域的发展,使视频生成和视频模型的研究获得了巨大进步。
下一步,便是用于训练机器人的世界模拟器。

从相同的起始图像序列开始,世界模型可以预测不同机器人动作导致的多个未来。

向左,向右,向前看~
它还可以预测重要的对象交互,比如刚体、对象掉落的效果、部分可观察性:

可变形对象(窗帘、衣物):

铰接对象(门、抽屉、窗帘、椅子):

世界模型解决了在构建通用机器人时一个非常实用但经常被忽视的挑战:评估。
如果你训练一个机器人执行1000项任务,怎样才能确定与以前的模型相比,新模型使机器人在所有1000项任务中都做得更好?
另外,由于环境背景或环境照明的细微变化,即使是相同的模型权重,也可能在几天内性能迅速下降。
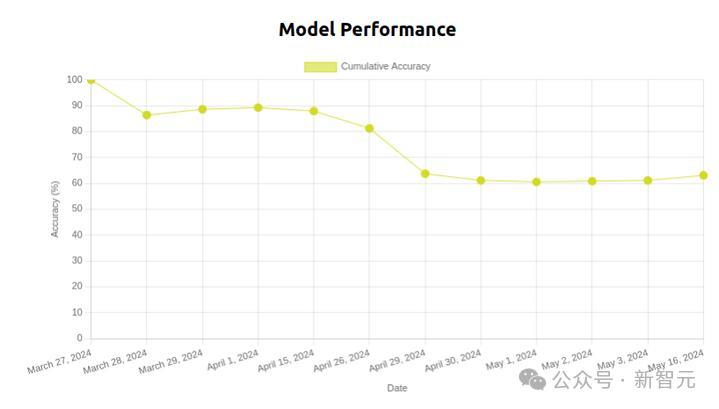
一个叠T恤模型在50天内的性能下降情况
如果环境随着时间的推移而不断变化,那么旧实验将不再可重现,尤其在家庭或办公室等不断变化的环境中,评估多任务系统将非常困难。
而如果没有办法进行严谨的评估,就无法预测增加数据、计算和参数量时,模型的能力将如何变化。
——机器人想要拥有自己的「ChatGPT时刻」, Scaling law必不可少。
基于物理的模拟
基于物理的模拟(Bullet、Mujoco、Isaac Sim、Drake)是快速测试机器人策略的合理方法,可重置、可重现。
但是,这些模拟器大多是为刚体动力学而设计的,
——如何模拟机器人手打开装有咖啡过滤器的纸板箱、用刀切水果、拧开冷冻的蜜饯罐或者与人类交互?

众所周知,家庭环境中遇到的日常物体和动物很难模拟,这些模拟器也缺乏现实世界用例的多样性,对real或sim中有限数量的任务进行小规模评估,并不能预测现实世界中的大规模评估。
正确的打开方式
直接从原始传感器数据中学习模拟器,并使用它来评估数百万个场景中的策略,无需手动创建即可吸收现实世界的全部复杂性。
——世界模型闪亮登场。

在过去的一年里,1X的研究人员收集了数千小时的EVE人形机器人数据(在家中和办公室执行各种移动操作任务,并与人互动),

将视频和动作数据相结合,训练了一个新的世界模型。

世界模型能够根据不同的动作命令生成不同的结果。
世界模型能够根据不同的动作命令生成不同的结果,其主要价值来自模拟对象交互。
比如下面这个例子,为模型提供相同的初始帧和三组不同的抓取操作。在每种情况下,被抓取的箱子都会根据抓手的运动被抬起和移动,而其他箱子则不受干扰。

即使没有提供操作,世界模型也会生成合理的视频,例如驾驶时应避开人和障碍物:

世界模型还可以生成长视距视频,比如完整的T恤折叠演示(T恤和可变形物体往往很难在刚体模拟器中实现)。
英伟达Cosmos分词器
分词器(Tokenizer)将冗余和隐式视觉数据映射到紧凑的语义token中,从而能够高效训练大规模生成模型,并在有限的计算资源上实现推理。
目前的一些开源视频和图像分词器经常产生糟糕的数据表示,导致有损重建、图像失真和视频时间不稳定,并限制了建立在分词器之上的生成模型的能力。
低效的分词过程还会导致编码和解码速度变慢,训练和推理时间变长,从而对开发人员的工作效率和用户体验产生负面影响。
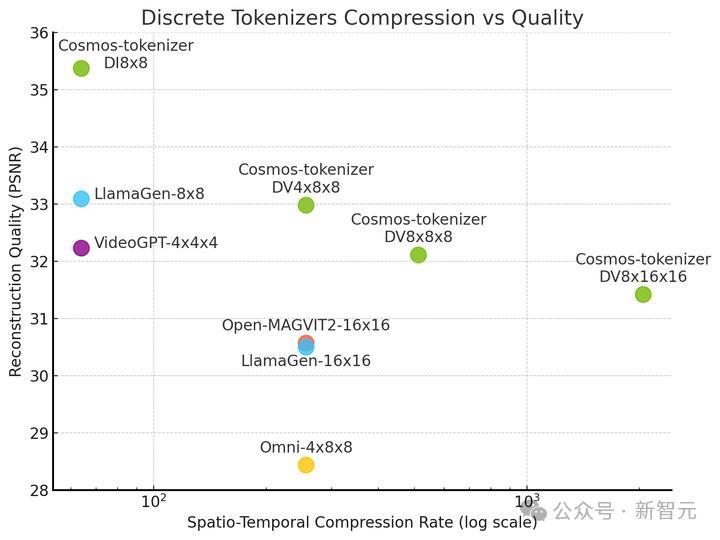
英伟达于近日开源了全新的分词器Cosmos,在各种图像和视频类别中提供了极高的压缩率和极高的重建质量。

Cosmos支持具有离散潜在代码的视觉语言模型(VLM)、具有连续潜在嵌入的扩散模型,以及各种纵横比和分辨率。
分词器架构
Cosmos分词器使用复杂的编码器-解码器结构,核心是一个3D因果卷积块,用于同时处理时空信息,并使用因果时间注意力来捕获数据中的长期依赖关系。
因果结构确保模型在执行分词时仅使用过去和现在的帧,避免将来的帧。这对于与许多现实世界系统的因果性质保持一致至关重要,例如物理AI或多模态LLM。
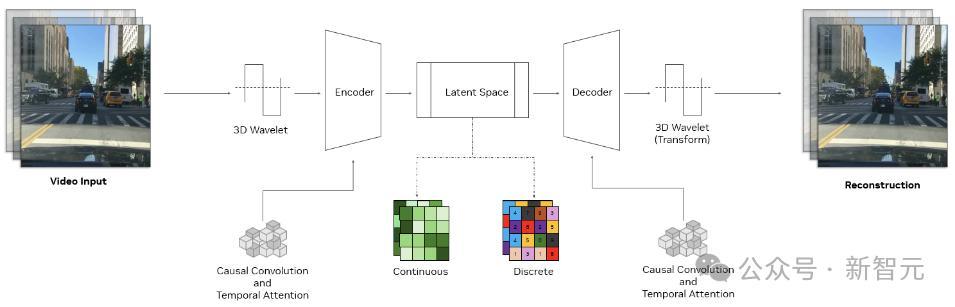
使用3D小波(可以更高效地表示像素信息的信号处理技术)对输入进行下采样,处理完数据后,逆小波变换会重建原始输入。
这种方法提高了学习效率,使分词器的可学习模块能够专注于有意义的特征,忽略多余的像素细节。
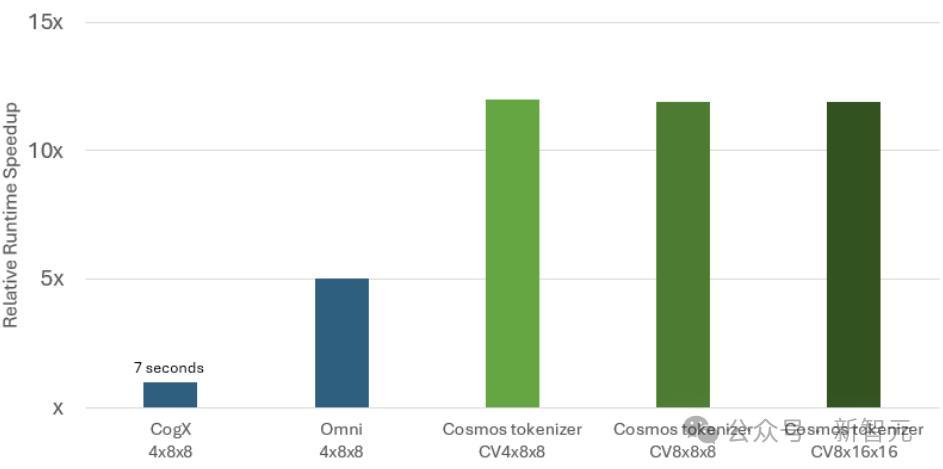
在推理测试中,与领先的开源分词器相比,Cosmos分词器的重建速度提高了12倍,显著降低了模型的运行成本。
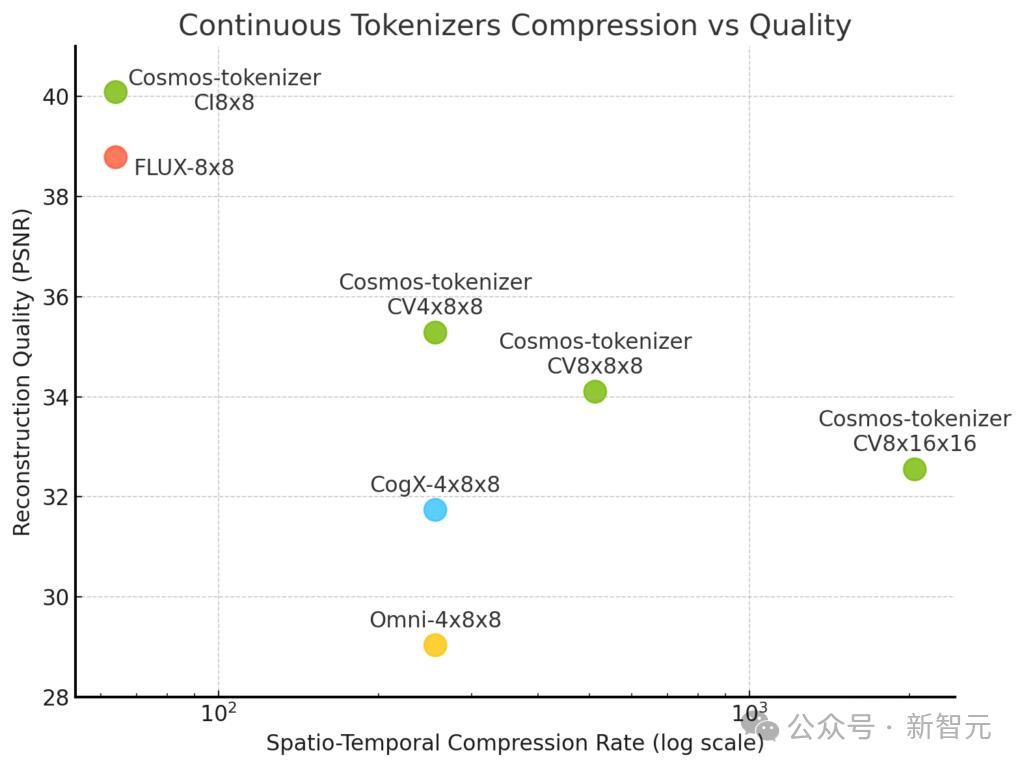
与连续型分词器PK:
与离散型分词器PK:
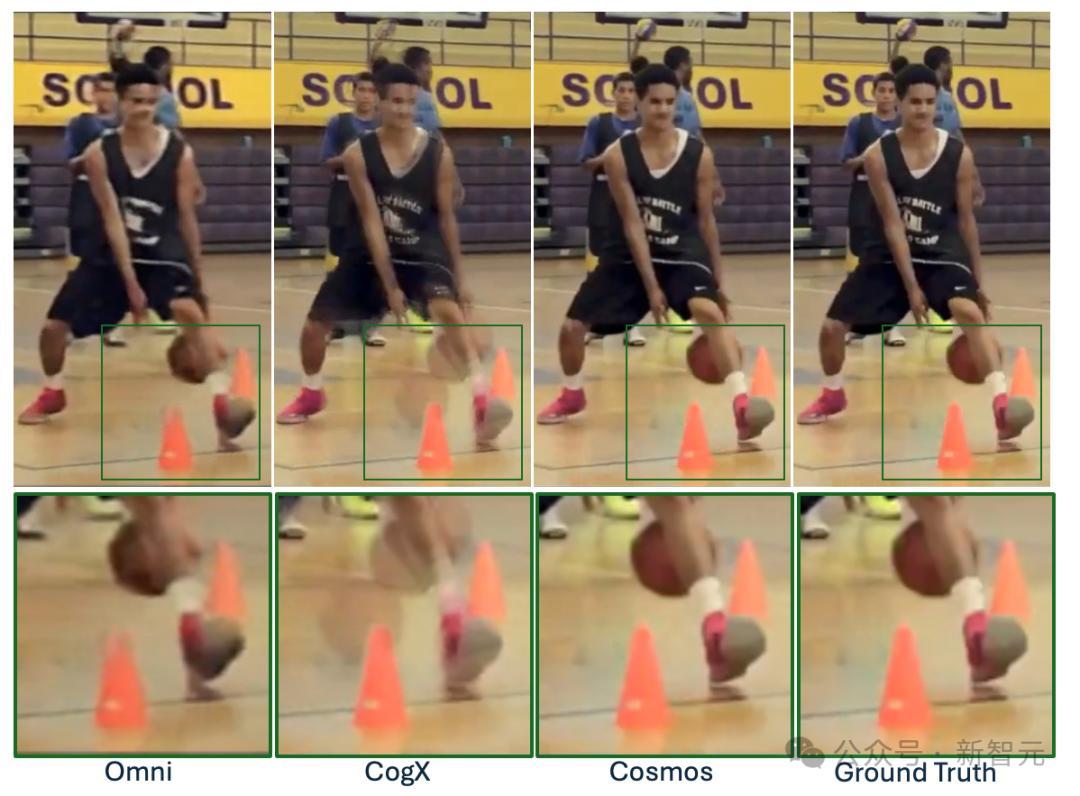
有图有真相:
参考资料:
https://x.com/ericjang11/status/1854226268763644148
https://www.1x.tech/discover/1x-world-model-sampling-challenge
https://github.com/NVIDIA/Cosmos-Tokenizer